7 min to read
Seismic Imaging Performance with AWS Graviton4
DevitoPRO performance portability from Graviton2 to Graviton4

With the general availability of AWS Graviton4, we explore its performance advancements over previous Graviton generations using DevitoPRO’s standard 3D acoustic wave propagation kernels. These Full Waveform Inversion (FWI) and Reverse Time Migration (RTM) propagation kernels, serve as benchmarks to develop cost models and assess computational efficiency.
The AWS Graviton4 exhibits substantial performance improvements compared to its predecessors. For 3D Isotropic acoustic, the AWS Graviton4 (r8g.24xlarge) delivers performance that is approximately 2.7 times faster than Graviton2 and 81% faster than Graviton3. In the 3D Fletcher Du Fowler TTI benchmark, the Graviton4 outperforms Graviton2 by over 3.4 times and is 51% faster than Graviton3. Similarly, the 3D Self-adjoint TTI benchmark on AWS Graviton4 runs nearly 3.6 times faster than Graviton2 and 80% faster than Graviton3.
These results underscore the significant generational improvements in the Graviton4, particularly for memory-bound high-performance computing applications.
Graviton4 - Amazon EC2 R8g Instances
The Amazon EC2 instance type r8g.24xlarge is a single socket Graviton4. The Graviton4 processors offer significant advancements over the Graviton3. The Graviton4 has 96 Neoverse V2 cores and a revamped memory subsystem, featuring 12 DDR5-5600 channels and a peak memory bandwidth of 536.7 GB/s, which is 75% higher than the Graviton3. These improvements are particularly beneficial for memory-bound HPC applications, such as finite-difference based FWI/RTM operators.
Compiling on Graviton using GCC-14.1
To optimize the performance of our benchmarks on the AWS Graviton4 processor, we built GCC 14.1 from source, rather than the system default for Amazon Linux 2023 (6.1.94-99.176.amzn2023.aarch64) which is GCC 11.4.1. GCC 14.1 has a range of improvements that enhance the compiler’s ability to leverage the advanced features of the Neoverse cores, particularly the Neoverse V2 architecture used in Graviton4.
Key enhancements in GCC 14 include improved support for vectorization and new optimizations that are tailored for Neoverse V2 cores. These improvements allow for better exploitation of the high memory bandwidth and increased core count in Graviton4, resulting in more efficient execution of high-performance computing workloads. Additionally, the release includes enhancements in auto-vectorization, which are particularly beneficial for memory-bound applications like seismic imaging and simulation tasks.
Devito uses the following GCC flags depending on the generation of Graviton to maximize performance on a given instance. As there is just one NUMA domain in all cases, we parallelizing with pure OpenMP.
Graviton2 (Neoverse-N1):
gcc-14 -mcpu=neoverse-n1 -O3 -g -fPIC -Wall -std=c99 -Wno-unused-result -Wno-unused-variable -Wno-unused-but-set-variable -ffast-math -shared -fopenmp
Graviton3 (Neoverse-V1):
gcc-14 -mcpu=neoverse-v1 -O3 -g -fPIC -Wall -std=c99 -Wno-unused-result -Wno-unused-variable -Wno-unused-but-set-variable -ffast-math -shared -fopenmp
Graviton4 (Neoverse-V2):
gcc-14 -mcpu=neoverse-v2 -O3 -g -fPIC -Wall -std=c99 -Wno-unused-result -Wno-unused-variable -Wno-unused-but-set-variable -ffast-math -shared -fopenmp
3D acoustic benchmarks
To evaluate the performance of the Graviton4, we conducted benchmarks using three standard 3D acoustic wave propagation kernels. These tests were run in single precision with OpenMP thread parallelism. Each benchmark was carefully autotuned to optimize parameters such as cache block size, and the best result from multiple runs was recorded.
These benchmarks are categorized based on their operational intensity. The isotropic acoustic benchmark is the simplest among them, commonly used in seismic imaging, and its performance is primarily influenced by memory bandwidth. The Fletcher-Du-Fowler TTI kernel, which is frequently utilized by hardware vendors for benchmarking, represents a moderate level of complexity. In contrast, the self-adjoint TTI kernel, designed for robustness and accuracy, is employed in production workloads, reflecting the most demanding computational requirements for acoustic FWI/RTM. This categorization allows for a comprehensive evaluation of performance across a spectrum of real-world scenarios.
All three benchmarks were run with a fixed problem size of dimensions 512x512x512, for a total of 400 time-steps, space-order 8 and time-order 2.
In the bar-chart below we show how the Graviton3 and Graviton4 performance relative to the Graviton2. The r6g.16xlarge, r7g.16xlarge,r8g.16xlarge all have 64 cores; this highlights the performance improvement per core. In contrast, the r8g.24xlarge (a single socket Graviton4) has a total of 96 cores. We can see some strong scaling limits running the isotropic acoustic benchmark as we go from r8g.16xlarge the r8g.24xlarge (~10% performance improvement). However, this does not appear to be an issue when running with more complex propagator kernels such as TTI.
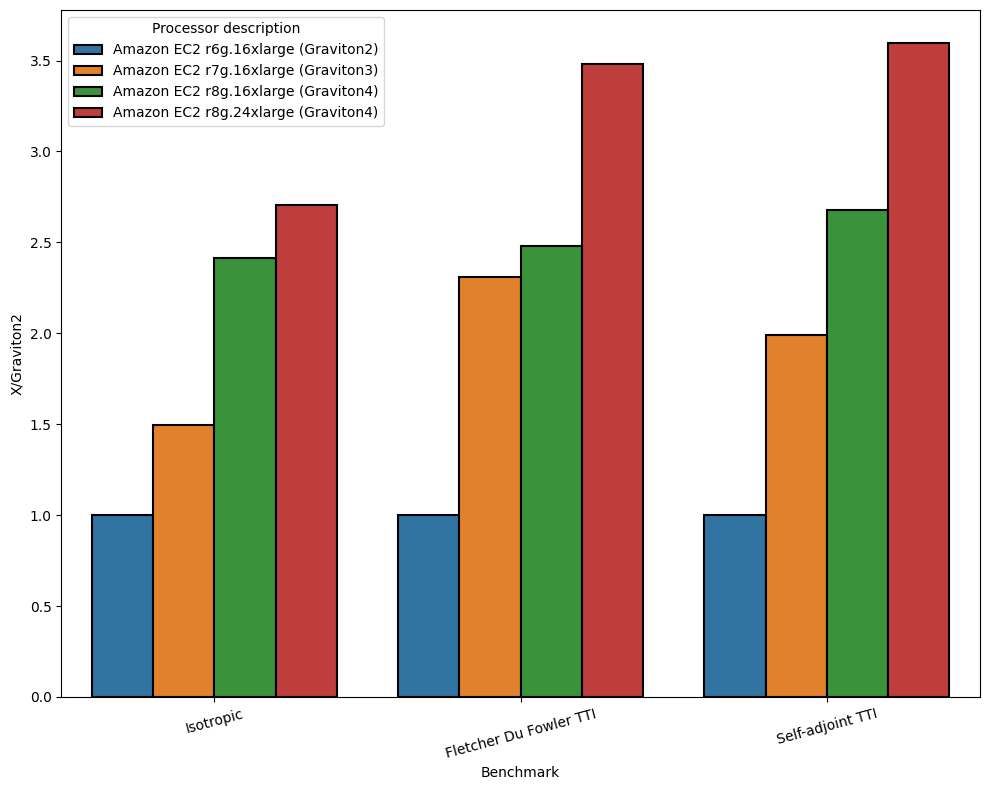
Price performance
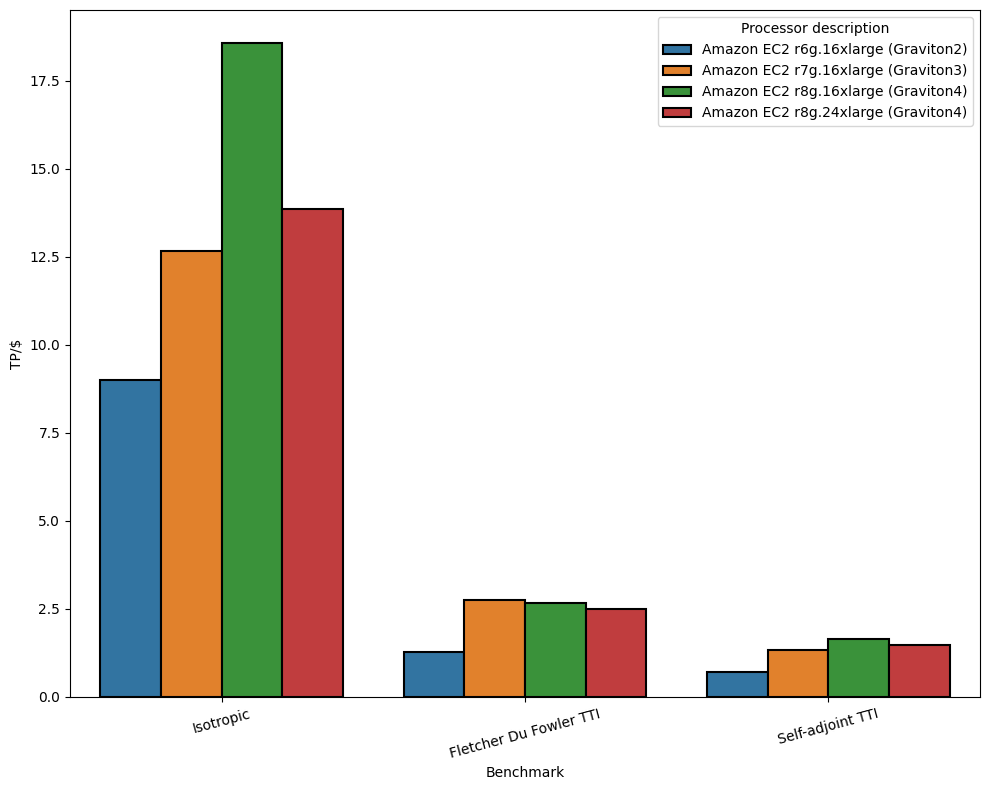
The overall picture for price-performance also looks good for AWS users, though there are some nuances. In the bar-chart below we use the AWS on-demand pricing for each instance and the benchmark performance in units of giga-points-per-second to create a tera-points-per-dollar (TP/$) benchmark metric. This is a measure of how much work you get done per dollar allowing users to get an estimate of the price-to-solution.
For the isotropic acoustic and the self-adjoint acoustic TTI, we can see that the Graviton4 delivers the highest throughput per dollar, followed by Graviton3 and Graviton2.
However, the Fletcher Du Fowler TTI benchmark presents an exception. In this case, Graviton3 provides the highest throughput per dollar, followed by Graviton4 and then Graviton2. Although both the isotropic acoustic and self-adjoint TTI benchmarks are 81% faster on Graviton4 than on Graviton3, the Fletcher Du Fowler TTI benchmark is only 51% faster on Graviton4 than on Graviton3. Given that the theoretical increase in memory bandwidth is 75%, this discrepancy warrants a deeper performance profiling analysis to understand why this particular benchmark underperforms relative to the other benchmarks.
Graviton4 r8g.16xlarge vs r8g.24xlarge
When choosing between the r8g.16xlarge and r8g.24xlarge instances, it is important to consider the specific characteristics of your workload. For workloads where the problem domain is too small to benefit from strong scaling across all available cores, allocating the entire node and running multiple shots per node can provide better value. This approach not only maximizes resource utilization but also helps avoid the potential impact of noisy neighbors in multi-tenant environments if r8g.16xlarge was instead used.
By fully utilizing the r8g.24xlarge instance, which contains all 96 cores of the Graviton4 processor, you can achieve more consistent performance, as the risk of resource contention from other tenants is minimized. This strategy ensures you get the best possible value from the Graviton4 architecture for your HPC tasks.
Conclusion
The benchmarking results clearly demonstrate the impressive capabilities of the AWS Graviton4 processor. With its increased core count and higher memory bandwidth, the Graviton4 significantly enhances the performance of high-performance computing (HPC) applications. Our benchmarks show that DevitoPRO, utilizing AWS Graviton4, achieves substantial performance gains over previous Graviton generations, particularly for memory-bound applications such as seismic imaging.
The Graviton4’s advancements in core architecture and memory subsystem allow DevitoPRO to run efficiently without requiring extensive modifications. This highlights the ease of integration and the high productivity potential that DevitoPRO offers for cutting-edge seismic imaging applications. The performance improvements observed across various benchmarks—3D Isotropic Acoustic, Fletcher Du Fowler TTI, and Self-adjoint TTI—underscore the generational leap in computational efficiency provided by Graviton4.
Moreover, the Graviton4 processor also offers favorable price-performance ratios, making it a cost-effective choice for demanding workloads. While certain benchmarks like Fletcher Du Fowler TTI indicate areas for further optimization, the overall enhancements in speed and throughput per dollar make Graviton4 an attractive option for HPC users.
Our work with AWS underscores our commitment to delivering top-tier performance across diverse hardware platforms, ensuring that our users can achieve the best possible outcomes in their seismic imaging and beyond.
Acknowledgements
Many thanks to the AWS team for their generous provision of credits and technical support, which made this benchmarking study possible. Their continued collaboration and support are invaluable in our ongoing efforts to optimize DevitoPRO for cutting-edge seismic imaging and high-performance computing applications.

